
Joins in Spanner: Advancing Performance Beyond the Basics
Harnessing Google Cloud Spanner's Power: Distributed Queries, Join Methods, and Performance Tips.
 showcases a majestic classicism building with columns, domes, and ornate facades, symbolizing traditional data structures. Panel 3 (right) features a sleek, towering modern skyscraper made of glass and steel, representing contemporary data formats. Panel 2 (center) presents a unique architectural fusion, visualizing a 'classical skyscraper' that combines elements of both classicism and modern design, with classical columns at the base transitioning to a modern glass and steel structure as it rises. This central hybrid building epitomizes the 'join' operation, illustrating the innovative integration of old and new data structures in Google Cloud Spanner.")
Joins are a powerful feature of SQL databases and often their greatest advantages over their NoSQL counterparts. They allow for ad-hoc data combinations without special design. Achieving the same in, for instance, Cloud Firestore would require significantly more effort on your part.
However, Spanner is not your typical SQL database. First, it is highly distributed, necessitating careful consideration when crafting join queries. Second, it doesn't fully support the SQL standard. In this article, we will examine what makes joins in Spanner special and how to optimize their performance.
Spanner's Distributed Nature
Spanner is a distributed database system. This architecture has implications for all executed queries, especially those covering multiple tables, such as joins.
Firstly, everything in Spanner can be viewed as a network call. Simplified: when you select columns, Spanner makes a network call to the server where the table resides, executes the query, and then transfers the data to you. Thus, if you join two tables, there's a high likelihood that those tables are stored on different servers. This scenario can result in a significant number of network calls. Given that networks are inherently unreliable, this can directly impact performance. You can gauge this by examining your query's execution plan. If it contains distributed operators, Spanner has to make several network calls to execute it. The fewer the network calls, the better the performance.
Let's examine how to minimize distributed operators in the first place.
Avoid Joins by Accident
Every time you use a secondary index and query for columns not in the index, Spanner does a back-join to get the missing columns. You can think of it as the index being a table that has the indexed column as a Key and the primary key of the original table as a Column. Spanner then uses a join between the index table and the original table to return the query result. If you only think about the index, this is counterintuitive.

There are three simple ways to mitigate the problem:
Split your query into two. First, use the secondary index to query for the IDs, then use the IDs to query the original table.
Use Stored Columns. By doing this, Spanner adds the Columns as unindexed fields to the Index Table, and therefore does not need to do a back-join on them.
Add the columns to the index itself.
Every solution has its pros 👍 and cons 👎. The first solution must be done on the application side but is very flexible. You do not have to alter the index at all.
The second solution - my preferred one - uses more disk space as the columns are effectively duplicated.

The third way has the same downsides as the second one, yet for each insert, the index must be updated on multiple columns, which is often slower than just storing the columns.
Design for Joins - Interleaved Tables
If you anticipate that certain tables will be frequently joined, for example, customers and shipping addresses, consider using interleaved tables in Spanner. When two tables are interleaved, Spanner stores them closely together, reducing the need for network calls.
However, this approach is only viable for genuine parent-child relationships. If you interleave table A and B, you cannot insert into table B without a corresponding parent in table A; thus, interleaved tables aren't suitable for every situation.
As this article focuses on the general join use case, we will not delve deeper into the topic of interleaved tables. For more details, please refer to the official documentation.
Join Methods in Spanner
Most of the time, we do not think about what happens if we type something like:
select A.*, B.Foo from A join B on A.B_ID = B.IDAnd to be honest, this is great because it reduces the cognitive load while using a database. However, as mentioned above, if you need a performant query, you have to invest some time and figure out what works best.
In the default scenario, Spanner’s query optimizer will choose the appropriate join type for your query,based on statistics collected in the background. However, if you add a new join, maybe on new tables, the optimizer does not have enough knowledge and you may want to enforce one join method to keep the performance up. You can do this with join hints:
select A.*, B.Foo from A join@{JOIN_METHOD=apply_join} B on A.B_ID = B.IDWe will take a closer look at different join types in Spanner right now. For illustrative purposes, we will use this join on the given schema:
SELECT c.FirstName, o.ProductName
FROM Customers c
JOIN Orders o ON c.CustomerID = o.CustomerID;CREATE TABLE Customers (
CustomerID INT64 NOT NULL,
FirstName STRING(255),
Email STRING(255)
) PRIMARY KEY (CustomerID);
CREATE TABLE Orders (
OrderID INT64 NOT NULL,
CustomerID INT64 NOT NULL,
ProductName STRING(255)
) PRIMARY KEY (OrderID);Hash Join 🔍
Hash Joins are a good choice if you want to join two large tables. A Hash Join runs in two phases.
First, it takes the “build” table (the table which has fewer rows, in our case, it's Customers) and creates an in-memory hash table where the hash key is derived from the join. In our scenario, the hash key will be based on CustomerID.
Then, the other table (“probe” table, Orders in our case) is scanned. For each row in Orders, the hash key of CustomerID is calculated and then searched in the Hash Table built previously. If there is a match, the row will be in the result set.
You can enforce a Hash Join in Spanner in two ways:
select A.*, B.Foo from A hash join B on A.B_ID = B.ID
select A.*, B.Foo from A join@{JOIN_METHOD=hash_join} B on A.B_ID = B.IDYou can provide additional join hints for Hash Joins:
HASH_JOIN_BUILD_SIDEwith valuesBUILD_LEFTandBUILD_RIGHTto decide which table should be used for the build side. By default, the first table (the one after from) will be used, which is equivalent toBUILD_LEFT.HASH_JOIN_EXECUTIONwithMULTI_PASS(default) andSINGLE_PASS. This is important if you reach the memory limit while building the Hash Table -SINGLE_PASSwrites the Hash Table to disk.

Hash Joins come with their advantages 👍 and disadvantages 👎.
On the pro side 👍
Hash Joins are very efficient for large datasets, especially if you expect that the join result will be large as well.
Hashing and probing the hash table are typically very fast.
On the cons side 👎
The Join performs a full table scan on the probe table. This is especially inefficient if only small parts of the tables are required for the join.
If the hash table does not fit into memory, it must be partially written and read from the disk, which is significantly slower.
Indexes on the join columns are not used! Thus, it does not make sense to create indexes on CustomerID and use Hash Joins simultaneously.
You can improve the performance 🚀 of a Hash Join by reducing the size of the build table with an appropriate WHERE condition. Adding an index to the columns in the WHERE condition will speed up creating the build table, but do not affect the underlying join.

Hash Joins are useful for large ad hoc joins and data analysis but may not be the best choice to fetch the orders for a single customer.
Apply Join 🔄🔁
Apply Joins, also known as Nested Loop Joins, work as follows: For each row in the left side (outer loop 🔄), the join condition is checked against every row in the right side (inner loop 🔁). For many developers, nested loops can be concerning due to their inherent inefficiency and quadratic runtime.
Apply Joins are effective when both tables are small or can be significantly reduced using WHERE conditions. For instance, a nested loop involving 4 rows on the left side and 5 rows on the right side is manageable.
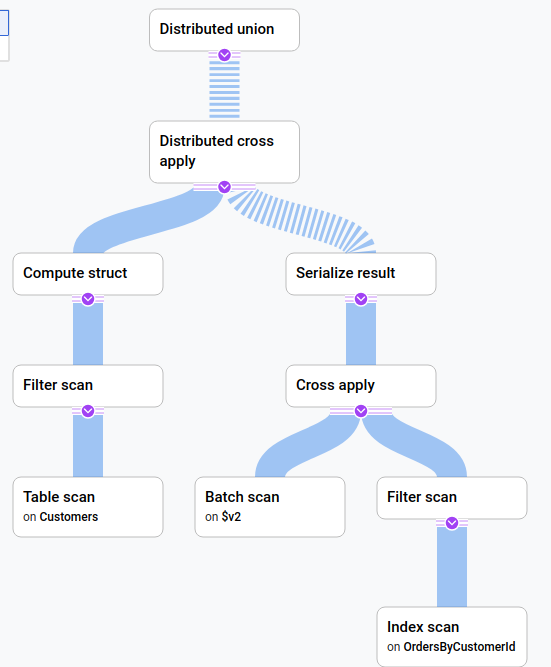
Apply Joins can also be optimized for larger tables. If the right side has an index on the join column, Spanner only needs to loop over the left side 🔄 and can use the index to fetch the rows from the right side efficiently. When the left side is narrowed down via an appropriate WHERE condition (ideally backed by an index), Apply Joins can efficiently handle larger tables. In some scenarios, they can be more efficient than Hash Joins, especially when a small subset of both tables is required.
You can enforce an Apply Join via:
select A.*, B.Foo from A join@{JOIN_METHOD=apply_join} B on A.B_ID = B.IDMerge Join ⛓️
A Merge Join takes both sides of the join and sorts them by the join columns. Spanner then reads the beginning of both sorted tables and compares them based on the join condition. If they match, the merged rows are added to the result set. If the join column of one table is smaller, that row is skipped, and the next row from that table is read. If you need another mental model, think of 🐍 Python's zip function, which works similarly (yet different).
A Merge Join is efficient if the data is already sorted or can quickly be sorted using an index on the join columns 🔍.
Similar to Hash Joins, a Merge Join performs a full table scan on both tables. Therefore, the downsides of both join types are alike. The performance comes from the fact that neither hashing nor looping is needed with the sorted tables. If you need only a small subset of both tables, consider an Apply Join first.

It's worth noting that a Merge Join is never choosen by the query optimizer by default, so you'll need to enforce it with:
select A.*, B.Foo from A join@{JOIN_METHOD=merge_join} B on A.B_ID = B.IDIn day to day work, Merge Joins are not likeley to be your first choice, but it is important to keep in mind that they exist.
Push Broadcast Hash Join 📡
A Push Broadcast Hash Join acts as the distributed version of a Hash Join 🔍. Although the merge logic remains the same as the standard Hash Koin, in this method, the build side is serialized into a batch and dispatched to all remote servers holding data from the probe side. Once received, the batch is deserialized and the Hash Join logic takes over. So, when is this approach preferable to a regular Hash Join?
Push Broadcast Hash Joins facilitate parallel processing of the join, potentially leading to swifter execution times. They tend to be more efficient when the build side is significantly smaller than the probe side. However, if both sides are of comparable size, transmitting the hash table to all other servers might introduce a network overhead that isn't counteracted by quicker query execution. Another consideration is data distribution. For instance, if 80% of the probe side data resides on one server and the remaining 20% is dispersed across multiple servers, the advantages might be negligible.

It's evident that this join type caters to specific scenarios, much like the merge join ⛓️. Consequently, it isn't selected by the query optimizer by default. To enable it, use:
select A.*, B.Foo from A join@{JOIN_METHOD=push_broadcast_hash_join} B on A.B_ID = B.IDJoin Performance Cheat Sheet 🚀
Now that we got to know the different join methods in Spanner, let us summarize how to improve join performance.
Trust the Query Optimizer 🧠: Let the query optimizer do its work first. Only optimize if you experience bottlenecks.
Reduce Left Side ⬅️: Try to reduce the left side of a join. Choose the smallest table as the left side if possible and reduce its size with a WHERE condition. Apply an index on the WHERE condition if suitable.
Use Stored Columns 🗄️: Utilize Stored Columns to minimize the number of back-joins required, especially when dealing with secondary indexes.
Understand Data Distribution 🌐: Be aware of how your data is distributed across servers. Avoid join methods that might introduce unnecessary network overhead due to data distribution.
Consider Indexes on Join Columns 🔍: Especially for Apply Joins and Merge Joins, having indexes on the join columns can significantly speed up the join operation.
Monitor and Analyze Execution Plans 📊: Regularly check the execution plans of your queries. Look for distributed operators or signs of full table scans, as they can indicate potential performance bottlenecks.
Data Volume and Query Frequency 📈: The efficiency of join operations can be influenced by the volume of data in your tables and the frequency of your queries. Large tables can slow down certain joins, especially if they're not optimized. If specific join queries are frequently executed, consider optimizing them regularly.
Conclusion 🌟
Thank you for exploring join optimizations in Spanner with me! If you found this enlightening, please give it a like ❤️, share your thoughts in the comments 💬, and subscribe for more insightful content. Your feedback truly motivates me! Happy querying! 🚀