
Scalability Cheat Sheet #2 - When Things go Wrong and Partitioning
Tackling Replication Lag ⏳, Write Conflicts ⚔️, and Partitioning 🧩

Building on the concepts covered in the first part, we’ll explore how to manage replication lag, resolve write conflicts, and efficiently partition data across multiple nodes.

These topics are critical for ensuring that your system remains responsive, reliable, and scalable as it grows.
In this post, you'll learn about:
⏳ Replication Lag: Understanding delays in data synchronization and how to mitigate them.
⚔️ Write Conflicts: How to handle conflicts in multi-leader and leaderless modes.
🔧 Fail-over Strategies: Ensuring continuous availability during node failures.
🧩 Partitioning: Dividing data efficiently across multiple nodes to handle Big Data and avoid hotspots 🌶️.
Replication Lag ⏳: Understanding Delays in Data Synchronization
Replication lag occurs when replicas have stale data due to delayed updates, common in async setups. It can also occur in leaderless setups depending on the consistency settings.
Leaderless systems like Amazon DynamoDB can mitigate lag through quorum reads and writes. In most systems, lag is typically only a few seconds, but it can be longer depending on performance vs. consistency needs.
Basic considerations 💡:
Some applications may not care about replication lag, depending on the use case.
If you always need strong consistent data, use synchronous replication.
A basic workaround: Divide reads into categories. For strong consistency, read from the leader; otherwise, read from replicas. For example, this is supported in Google Cloud Spanner.
Types of Consistency 🧱:
Read-After-Write 📚: Ensures that the user who wrote
xnever reads an older version ofxafter its write. Suitable when users mainly write small portions, like their profile.Monotonic Reads ↗️: Ensures that if a user reads
xat a given time, they won’t see older versions ofxlater. Often implemented by assigning the same replica to a user, e.g., based on a hash of the user ID. This method can fail if the assigned replica is down.Causal Consistency 🔗: Ensures users see data in the correct causal order, such as never seeing an answer before a question.
Configurable Consistency Modes: Many databases allow you to adjust consistency levels, giving flexibility to meet specific needs. Examples include Amazon DynamoDB, Apache Cassandra, MongoDB, Cosmos DB, Riak, and Couchbase.
Leaderless Systems 🤷♂️: Rely on additional processes to manage consistency and mitigate lag:
Read Repair 👩🔧: Fixes inconsistencies during read operations by updating stale replicas with the latest data.
Anti-Entropy Processes 🛠️: Periodically synchronize replicas to ensure they converge to the same data.
We will discover Consistency in the upcoming Cheat Sheet post in more detail.
As we’ve seen, replication lag is a manageable challenge with the right consistency models and strategies.
Write Conflicts ⚔️ and Their Resolution: Keeping Your Data Consistent
Write conflicts happen in multi-leader and leaderless modes when nodes accept writes independently. Resolving these conflicts is key to maintaining consistency across replicas.
How They Happen 🔍:
Concurrent Writes 📝: Multiple nodes write to the same data simultaneously without coordination.
Network Partitions 🌐: Nodes become temporarily disconnected and accept conflicting writes.
Timing Issues ⏱️: Variations in the timing of updates can cause mismatched data versions across nodes.
Common Resolution Strategies 🚑:
Avoiding Conflicts Altogether: Assigning a responsible leader for each record can help avoid conflicts, similar to a partitioned leader approach. This approach fails if the leader goes down.
Last Write Wins ⏱️: Each write is timestamped, and the highest timestamp wins. Drawbacks include potential data loss if writes are overwritten.
Merging Data 🫂: If feasible, merge conflicting writes. Often requires additional application logic.
Conflict-Free Replicated Data Types (CRDTs) 🤖: Data structures designed to resolve conflicts automatically. Complex and less supported in many databases.
Align your conflict resolution method with your application's specific needs, whether prioritizing speed, simplicity, or data accuracy.
Failover 🔧: Ensuring Continuous Availability During Failures
Failover is the process of switching to a backup when a primary or follower node fails, ensuring high availability and minimal downtime in distributed systems. It covers both leader and follower nodes to maintain seamless operation.
Failed Followers: Mostly easy to recover. After the follower becomes available again, it requests all data from a leader that has been written since the failure. This assumes that the follower was previously synchronized up to a specific point; longer downtimes or high data volumes can complicate recovery.
Leader Failover 👑: More complex.
Automatic: The system promotes a follower to a leader.
Manual: A human decides who will be the new leader.
Split Brain 🧠: Must be avoided to prevent multiple nodes from incorrectly assuming the leader role simultaneously, which can lead to data inconsistencies.
Failure Detection: It is challenging to determine if a leader failed. Typically, a timeout is used; if the leader does not respond within a set number of seconds, it is assumed to have failed.
Consensus Algorithms 🤝: Used for leader election but are a topic on their own and out of scope here. Common algorithms include Raft and Paxos.
Handling write conflicts is crucial for maintaining consistency in multi-leader and leaderless setups. With these resolution strategies in mind, let’s move on to explore failover strategies
Partitioning 🧩: Dividing and Conquering Data
Partitioning divides data across multiple nodes using a partitioning key, essential for managing large datasets where a single machine can't handle all the data —common in Big Data scenarios.
How it works:
Each record belongs to a partition (shard)
Partitions are typically replicated for availability and fault tolerance.
The goal is to distribute both data and load evenly across nodes, avoiding skewed partitions (uneven data or load) and hotspots 🌶️ (partitions bearing most of the load).
Sometimes called Sharding
Key-Value Data Partitioning 🔑
Partitioning by Key Range 📏: Assigns each partition a range of keys (e.g., A-D, E-F).
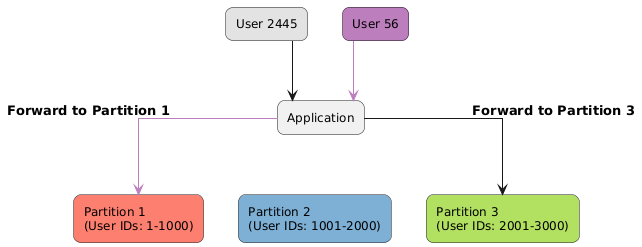
Partitioning by Key Range Ranges can vary in size and may be set manually or automatically.
✅ Maintains sorted data, making range queries straightforward
❌ Can lead to hotspots 🌶️ if many keys fall within narrow ranges.
Partitioning by Hash Key 🎲: Uses a hash of the key to determine the partition.
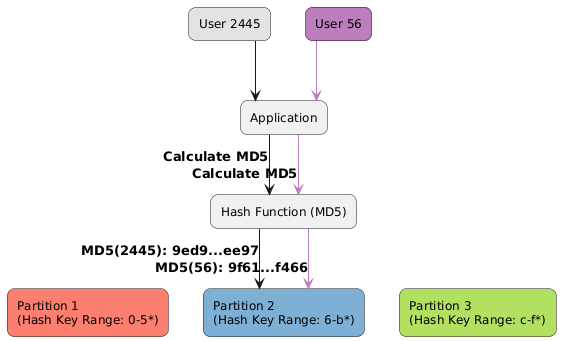
Partitioning by Hash Key ✅ Ensuring even distribution across nodes.
✅ This gives well-balanced data, depending on the hash function.
❌ Makes range queries inefficient due to random distribution.


Challenges and Solutions 🚧
Reducing Hotspots 🌶️: Prefixing keys with numbers or other identifiers (e.g., 00-99) can spread them across multiple partitions, distributing the load more evenly. However, this complicates reads, requiring the application to merge data from various partitions.
Secondary Indexes 📚: Secondary indexes don't naturally align with partitions since they're independent of the partitioning key. They can be handled by:
Local Index (Partitioning by Document) 📄: Each partition maintains its index.
Queries must hit all partitions as the client can't know where the data resides.
Optimizations like routing information or query hints can sometimes reduce the need to query every partition.
Global Index (Partitioning by Term) 🌐: The index is partitioned by the index keys themselves, allowing more targeted queries but complicating writes as they may span multiple partitions.
Rebalancing ⚖️: Maintaining Even Distribution
As data grows or nodes are added, partitions can become unbalanced, necessitating rebalancing to distribute the load evenly:
Fixed Number of Partitions 📦:
Set a fixed number of partitions upfront, often more than the number of nodes.
New nodes take over some partitions; departing nodes return them.
Too many partitions increase overhead, while too few limit scalability.
Dynamic Number of Partitions 🔄:
Partitions split if they exceed a size threshold or merge if they shrink too much.
Works well for key range partitioning but can cause frequent rebalancing during growth.
Rebalancing Costs 💸:
Moving data across partitions can be resource-intensive.
Prefer manual rebalancing during low-traffic periods to minimize impact.
Key Takeaways 📌
Replication Lag ⏳ is a common issue in asynchronous and leaderless setups, where replicas may have outdated data due to delayed updates, affecting data consistency.
Consistency Models: Various consistency levels, such as Read-After-Write, Monotonic Reads, and Causal Consistency, address different needs and scenarios in distributed systems.
Write Conflicts ⚔️ occur in multi-leader and leaderless modes due to concurrent writes, network partitions, or timing discrepancies, requiring strategies like "Last Write Wins," data merging, or CRDTs for resolution.
Failover 🔧 ensures high availability by switching to backups during node failures. Leader failover is particularly complex and demands robust processes to avoid split brain scenarios and ensure seamless leader election.
Partitioning 🧩 divides data across multiple nodes, essential for handling large datasets in distributed systems, and requires careful management to distribute data and load evenly, avoiding hotspots 🌶️.
Rebalancing ⚖️ is crucial as data grows or when adding nodes, redistributing data to maintain balance and efficiency, with strategies for fixed or dynamic partition numbers to adapt to changing loads.
If you found this guide helpful, please share it and drop your thoughts in the comments below—I'd love to hear your feedback!
In the upcoming post, I’ll pull together my notes on Consistency to create a new cheat sheet.
Great article. I believe you could have mentioned consistent hashing as a superior partitioning algorithm that reduces rebalancing costs when you change the number of data nodes in your cluster.